
This is again a big win on the red team at least for me. They developed a “fully open” 3B parameters model family trained from scratch on AMD Instinct™ MI300X GPUs.
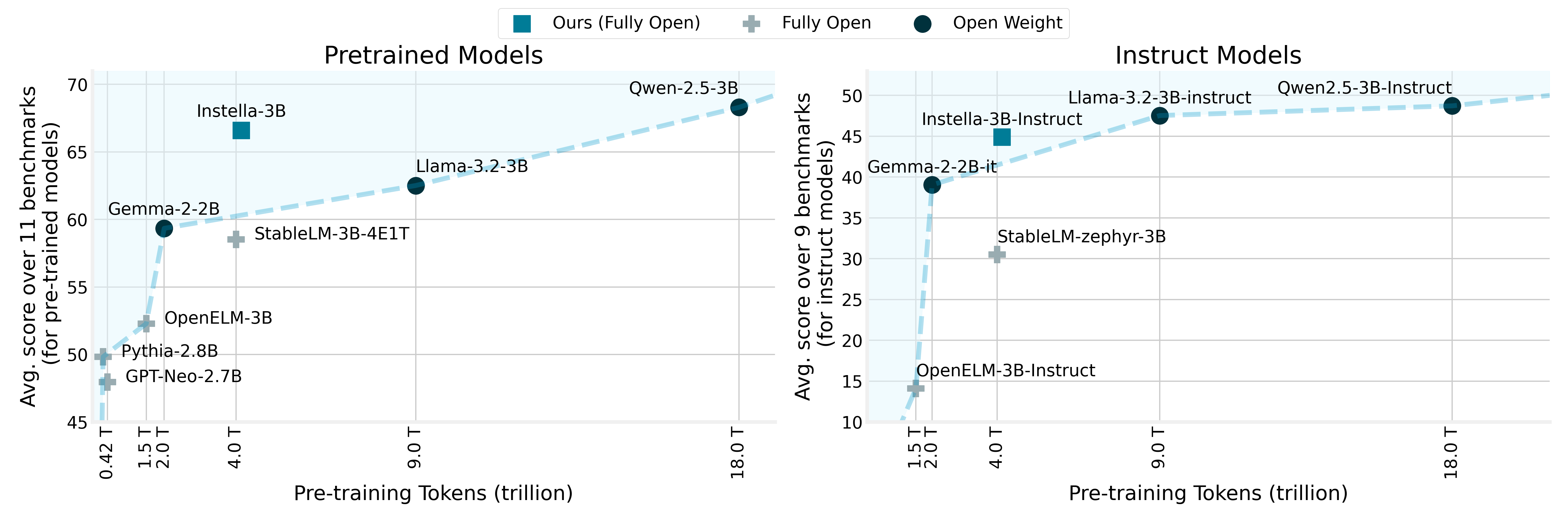
AMD is excited to announce Instella, a family of fully open state-of-the-art 3-billion-parameter language models (LMs) […]. Instella models outperform existing fully open models of similar sizes and achieve competitive performance compared to state-of-the-art open-weight models such as Llama-3.2-3B, Gemma-2-2B, and Qwen-2.5-3B […].
As shown in this image (https://rocm.blogs.amd.com/_images/scaling_perf_instruct.png) this model outperforms current other “fully open” models, coming next to open weight only models.
A step further, thank you AMD.
PS : not doing AMD propaganda but thanks them to help and contribute to the Open Source World.
Help me understand how this is Open Source? Perhaps I’m missing something, but this is Source Available.
Instead of the traditional open models (like llama, qwen, gemma…) that are only open weight, this model says that it has :
Fully open-source release of model weights, training hyperparameters, datasets, and code
Making it different from other big tech “open” models. Tough it exists other “fully open” models like GPT neo, and more
Properly open source.
The model, the weighting, the dataset, etc. every part of this seems to be open. One of the very few models that comply with the Open Software Initiative’s definition of open source AI.
Look at the picture in my post.
There was others open models but they were very below the “fake” open source models like Gemma or Llama, but Instella is almost to the same level, great improvement
Nice and open source . Similar performance to Qwen 2.5.
(also … https://www.tomsguide.com/ai/i-tested-deepseek-vs-qwen-2-5-with-7-prompts-heres-the-winner ← tested DeepSeek vs Qwen 2.5 … )
→ Qwen 2.5 is better than DeepSeek.
So, looks good.Dont know if this test in a good representation of the two AI, but in this case it seems pretty promising, the only thing missing is a high parameters model
Nice. Where do I find the memory requirements? I have an older 6GB GPU so I’ve been able to play around with some models in the past.
Following this page it should be enough based on the requirements of qwen2.5-3B https://qwen-ai.com/requirements/
LMstudio usually lists the memory recommendations for the model.
No direct answer here, but my tests with models from HuggingFace measured about 1.25GB of VRAM per 1B parameters.
Your GPU should be fine if you want to play around.
3B
That’s one more than 2B so she must be really hot!
/nierjokes
AMD knew what they were doing.
Can’t judge you for wanting to **** her or whatever, just don’t ask her for freebies. She won’t care if you are a human at that point.
That’s a real stretch. 3B is basically stating the size of the model, not the name of the model.
Are you calling her fat?
And we are still waiting on the day when these models can actually be run on AMD GPUs without jumping through hoops.
That is a improvement, if the model is properly trained with rocm it should be able to run on amd GPU easier
In other words, waiting for the day when antitrust law is properly applied against Nvidia’s monopolization of CUDA.
I know it’s not the point of the article but man that ai generated image looks bad. Like who approved that?
Oh yeah you’re right :-)




{kind=link}